
Cena que vivo no dia a dia construindo agentes para automação de atendimento. O usuário entra na conversa, diz no terceiro turno que prefere comunicação por WhatsApp e não por e-mail. O agente concorda. Cinco dias depois, em uma nova sessão, o agente envia um e-mail. A reclamação chega. A defesa do time é a clássica: "mas a janela de contexto era de 200 mil tokens, ele tinha tudo lá."
Tinha tudo lá. E mesmo assim esqueceu. Esse é o problema central da memória em agentes de IA, e o problema que a maioria dos times brasileiros ainda não tratou seriamente.
A pesquisa do último ano mostra com método o que eu venho vendo na prática. A Chroma testou 18 modelos de fronteira em 2026 e todos pioram conforme o input cresce. Um modelo de 200 mil tokens de janela degrada significativamente já em 50 mil tokens reais de contexto. Estudo da Stanford documentou queda de precisão de 70-75% para 55-60% com apenas 20 documentos recuperados via RAG (Chroma Research, 2026). Janela grande não é memória. E o agente que confia só na janela vai esquecer o que importou.
O problema: por que memória é difícil para agentes
LLMs são stateless por natureza. Cada chamada começa do zero. O que dá ilusão de continuidade é o histórico de mensagens reenviado a cada turno. Em uma conversa curta, isso funciona. Em conversas longas (atendimento corporativo, assistente pessoal, pipeline de automação que roda por semanas), o histórico bruto vira problema.

Existem três modos de falha clássicos.
Primeiro, context overflow. A janela técnica do modelo esgota. Acima de 200 mil tokens, alguns modelos simplesmente cortam o que vem depois. O agente perde memória de tudo o que aconteceu antes do corte, sem aviso.
Segundo, context rot. A janela ainda comporta, mas o conteúdo virou ruído. Chamadas antigas de ferramenta. Pensamentos intermediários descartados. Mensagens redundantes que repetem coisas que já estavam ditas. O modelo fica distraído pelo passado irrelevante e perde foco na tarefa atual. Pesquisa da Anthropic mostrou que contextos acima de 100 mil tokens degradam a qualidade do raciocínio mesmo quando tecnicamente cabem. O termo context rot foi cunhado em 2024 e virou o calcanhar de Aquiles que ninguém aborda nas demos.
Terceiro, custo exponencial. Cada turno reenvia o histórico inteiro. Em um agente que faz dezenas de chamadas de ferramenta por sessão (coding, browser automation, pesquisa), a conta de API estoura em poucas horas. Já vi clientes brasileiros pagando R$ 800 por dia em um único agente porque ninguém implementou compressão.
O survey acadêmico mais recente publicado em 2026 sobre o assunto sintetiza:
"Context length is not memory. Despite 200k-token windows, long-context models consistently underperform purpose-built memory systems on tasks requiring selective retrieval."
O benchmark LongMemEval (ICLR 2025) quantificou o estrago empiricamente: assistentes comerciais e LLMs de contexto longo mostram queda de 30% a 60% de precisão quando testados em memória de longo prazo através de múltiplas sessões.
A taxonomia de memória que você precisa entender
Antes de falar de solução, vale alinhar vocabulário. A literatura acadêmica organiza memória em quatro tipos, análogos à cognição humana. Quem está construindo agente precisa diferenciar os quatro.

Working memory é o conteúdo ativo na janela de contexto atual. A analogia humana é a memória de curto prazo, ou a RAM do computador. É a conversa que está acontecendo agora. Tudo que entra aqui paga o custo do token cheio.
Episodic memory é a memória de experiências concretas, com timestamp e contexto. Análoga à memória episódica humana ("lembro que terça-feira o usuário disse X"). É o tipo de memória que mais falta nos LLMs de hoje, segundo o paper "Episodic Memory is the Missing Piece for Long-Term LLM Agents" (2025).
Semantic memory é conhecimento abstrato, descontextualizado. Análoga aos fatos gerais que "você sabe" sem lembrar onde aprendeu. Em agente, isso vira regras consolidadas sobre o usuário: "prefere comunicação por WhatsApp", "usa formato DD/MM/YYYY", "é crítico em relação a roadmap de longo prazo".
Procedural memory é habilidade, script, plano reutilizável. Como andar de bicicleta, você sabe fazer sem precisar lembrar de cada passo. Em agente, isso vira skills, AGENTS.md, templates de workflow, slash commands. Já tratei desse tipo em outro artigo sobre os componentes do coding agent.
O problema mais difícil dentro dessa taxonomia é a consolidação: como transformar memória episódica (concreta, específica) em memória semântica (abstrata, generalizada). Quando o usuário menciona uma preferência três vezes em sessões diferentes, isso deveria virar um fato consolidado, não três episódios isolados. Comprimir agressivamente perde detalhes importantes. Armazenar tudo paga ruído que vira context rot. Sem princípios de consolidação, qualquer sistema oscila entre os dois extremos. O survey de 2026 é direto:
"A cada passe de compressão, detalhes de baixa frequência mas alta importância tendem a desaparecer."
As abordagens tradicionais e por que não bastam
A indústria já tentou três abordagens principais. Cada uma resolve parte do problema e cria outra.
Last-N messages. Mantém apenas as últimas N mensagens da conversa. Simples de implementar. Funciona em atendimento curto. Quebra catastroficamente em conversa longa: o usuário menciona preferência no turno 1, no turno 50 o agente perdeu completamente.
Semantic recall via RAG (Retrieval-Augmented Generation). Embute mensagens antigas em um índice vetorial e recupera as mais semanticamente parecidas com a pergunta atual. É a abordagem mais comum em produção hoje, e o assunto de um artigo anterior meu onde mostrei que a maioria dos RAGs de empresa está rodando sem gerações atrás.
Para memória de agente, o RAG ingênuo tem quatro problemas que vejo na prática:
- Retrieval impreciso. Embeddings de conversa agrupam por similaridade semântica, não por relevância temporal ou causal. O fragmento certo frequentemente não é recuperado.
- Sem ordenação temporal. Os chunks recuperados chegam fora de ordem. O agente não sabe o que aconteceu antes ou depois.
- Contexto fragmentado quebra cache. Chunks diferentes injetados a cada turno quebram o prefixo do prompt, inviabilizando o prompt caching dos grandes provedores.
- Infraestrutura adicional. Vector store (Qdrant, Pinecone, pgvector), pipeline de embedding, lógica de chunking. Custo operacional alto pra time pequeno.
Contexto longo puro. Manda todas as 500 sessões para o modelo a cada turno. Em teoria funciona. Na prática, é proibitivamente caro e perde qualidade acima de aproximadamente 100 mil tokens reais por causa do context rot. Janela de 1 milhão de tokens não resolve o problema. Resolve o problema de ter espaço pra falhar.
Observational Memory: a abordagem que está mudando o jogo
A Mastra (framework TypeScript para agentes, 300 mil downloads por semana em maio de 2026) publicou uma proposta que resolve essas limitações de forma elegante, chamada Observational Memory (OM). O princípio central vem da cognição humana:
"Humanos não lembram de tudo. Lembram do que importou. O resto vai para o esquecimento produtivo."
Em vez de recuperar pedaços do passado (RAG) ou manter tudo cru (contexto longo), a OM transforma progressivamente o histórico em um log estruturado de observações, usando dois agentes especializados rodando em background.
A arquitetura tem três camadas, organizadas do menos comprimido (em baixo) ao mais consolidado (em cima).
Camada 3, Message History. As últimas mensagens, ainda não processadas. Conteúdo bruto, recente. Cresce até o threshold.
Camada 2, Observations. Log denso de eventos, sinalizado por emoji de prioridade (crítico: decisões, preferências firmes, erros; relevante: detalhes de projeto, contexto de tarefa; informação geral: contexto de baixa urgência; concluído: tarefa finalizada).
Camada 1, Reflections. Padrões consolidados sobre o usuário, sínteses cross-sessão. É aqui que episódico vira semântico.
O detalhe arquitetural mais importante é que as camadas 1 e 2 são append-only. Só crescem ao final, nunca mudam o que já está lá. Isso significa que o prefixo do prompt fica estável entre turnos, condição necessária para que o prompt caching dos provedores (Anthropic, OpenAI) funcione com cache-hit consistente.
A consequência prática é direta: o custo despenca. Anthropic dá 90% de desconto em tokens cacheados. OpenAI dá 50%. Combinado com a compressão (3x a 40x dependendo do tipo de conteúdo), o custo por turno cai em 4x a 10x comparado a message history bruto sem caching.
Os dois agentes: Observer e Reflector
Aqui é onde a arquitetura vira interessante de explicar pra quem nunca olhou. Em vez de um único agente fazendo tudo, a OM separa o trabalho em dois agentes que rodam em background, em ritmos diferentes.
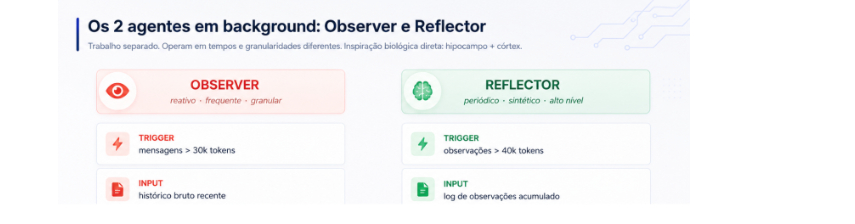
O Observer
O Observer é um agente especializado em uma única tarefa: ler mensagens brutas e converter em observações atômicas.
Quando ativa: quando o bloco de mensagens recentes ultrapassa o threshold (padrão de 30 mil tokens). Com buffering assíncrono ativado, o Observer começa a pré-computar observações em background quando o histórico atinge 20% do threshold, ou seja, em 6 mil tokens. Quando o limite chega, as observações já estão prontas. Zero latência perceptível pro usuário.
O que produz: notas atômicas estruturadas, cada uma com três informações.
- Prioridade via emoji. Sistema de sinalização inspirado em logging de software. Cada observação ganha crítico, relevante, informação geral ou concluído.
- Ancoragem temporal tripla. Data da observação (quando o Observer processou). Data referenciada (quando o evento de fato aconteceu). Offset relativo recalculado dinamicamente na função ("2 dias atrás", "semana passada"). Isso é o que faz a OM ganhar de qualquer RAG em raciocínio temporal.
- Conteúdo atômico. Uma observação igual a um fato. Não é parágrafo, é linha de log.
Exemplo concreto de output do Observer:
[2026-05-10 | ref: 2026-05-08 | 2 dias atrás] Usuário confirmou que quer
deploy apenas para staging até validar com o cliente.
[2026-05-10 | ref: 2026-05-10 | hoje] Arquivo auth.ts foi refatorado,
3 funções movidas para utils/token-helpers.ts
[2026-05-10 | ref: 2026-05-09 | ontem] Usuário mencionou que usa Windows
no pessoal, mas Mac no trabalho.
[2026-05-10] Setup do banco PostgreSQL concluído e testado.
O modelo padrão usado pelo Observer é o gemini-2.5-flash, rápido e com janela de 1 milhão de tokens (consegue processar histórico longo sem truncar). É customizável, e o Mastra entrega seleção de modelo por tier de tokens via ModelByInputTokens, conversa curta usa modelo barato, conversa longa usa modelo mais capaz.
O Reflector
O Reflector é o segundo agente. Atua sobre as observações, não sobre as mensagens brutas.
Quando ativa: quando o bloco de observações ultrapassa o threshold (padrão de 40 mil tokens). Nesse ponto, as observações já são log acumulado de muitas sessões.
O que faz: três operações cognitivas distintas.
Consolidação. Combina observações relacionadas em uma só. Três observações de "usuário mencionou preferir TypeScript" viram uma só: "usuário fortemente prefere TypeScript".
Descarte seletivo. Usa a prioridade por emoji pra eliminar de cima pra baixo: concluído e obsoletos saem primeiro, marcados como concluído ou superados por outra observação mais recente.
Reflexão de padrão. Identifica tendências, comportamentos recorrentes, padrões emergentes. É aqui que episódico vira semântico. Fatos concretos de múltiplos episódios são sintetizados em conhecimento abstrato sobre o usuário.
Exemplo concreto de reflexão:
[Padrão identificado, 2026-05-12]
Usuário tende a revisar decisões de arquitetura após ver código funcionando.
Preferência por "prototype first, decide depois".
Recomendado: apresentar implementações mínimas antes de propor refatorações.
A separação entre Observer e Reflector tem razão arquitetural clara. Operam em tempos e granularidades diferentes. O Observer é reativo e frequente. O Reflector é periódico e sintético. Unir os dois em um único agente forçaria sacrificar granularidade ou velocidade.
LongMemEval: o benchmark que provou
Tudo isso seria conversa fiada se não houvesse benchmark sério pra medir. LongMemEval é o benchmark canônico pra memória de longo prazo em assistentes de chat, publicado no ICLR 2025 por Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang e Dong Yu.
O benchmark mede cinco habilidades específicas, todas críticas pra memória de agente em produção:
- Information Extraction. Recall de fato mencionado 20 ou mais sessões atrás. Mede volume de ruído filtrado.
- Multi-Session Reasoning. Sintetizar informação de três sessões diferentes pra responder uma pergunta. Mede integração cross-temporal.
- Temporal Reasoning. Entender quando algo aconteceu e a relação temporal entre eventos. LLMs são notoriamente ruins nisso, e esta categoria expõe isso.
- Knowledge Updates. Lembrar que uma preferência X foi mudada para Y. Last-write-wins deve prevalecer, mas a maioria dos sistemas falha aqui.
- Abstention. Reconhecer que a informação não existe e não alucinar resposta. Mede a disciplina do sistema em dizer "não sei" quando deveria.
São três datasets. O longmemeval_s tem 115 mil tokens por questão e cerca de 40 sessões, cabendo em janela de 128k. O longmemeval_m tem 1,5 milhão de tokens e 500 sessões, e desafia até o GPT-5. O longmemeval_oracle traz só as evidências e serve como teto teórico de comparação.
Os resultados de maio de 2026:
- Mastra OM com GPT-5-mini: 94,87% overall, 95,5% em temporal reasoning. Score mais alto já registrado no benchmark, com qualquer sistema, com qualquer modelo.
- Mastra OM com Gemini-3-pro: 93,27% overall.
- Mastra OM com GPT-4o: 84,23% overall, ~75% em temporal reasoning.
- Oracle baseline (GPT-4o, dataset filtrado): ~82%. Referência teórica do "máximo possível" pelo benchmark.
- Mastra RAG (GPT-4o): 80,25% overall.
- Supermemory (GPT-4o): ~81,5% overall.
- LLMs comerciais sem sistema de memória dedicado (baseline): entre 50% e 70%, com queda documentada de 30 a 60 pontos percentuais ao mover de sessão única pra múltiplas sessões.
O número que mais me marcou: com GPT-4o, a OM superou o oracle em 2 pontos percentuais. Oracle recebe só as sessões que contêm a resposta. A OM processou 50 sessões completas e ainda assim acertou mais. Isso sugere que o contexto adicional das outras sessões, aparentemente irrelevante, na verdade ajuda no raciocínio quando adequadamente comprimido. O contra-intuitivo, mas tem sentido cognitivo: humanos também usam contexto adjacente pra inferir resposta correta.
OM x RAG x Contexto Longo
Vou comparar nas sete dimensões que mais importam pra agente em produção. Em cada uma, mostro como RAG, contexto longo e Memória Observacional se posicionam.
Precisão em memória de longo prazo. RAG fica em torno de 80% no LongMemEval. Contexto longo varia muito e degrada acima de 100k tokens reais. Memória Observacional chega a 95%. Vence pela margem.
Raciocínio temporal. RAG é fraco porque os chunks chegam fora de ordem. Contexto longo é médio. Memória Observacional é forte, justamente por causa da ancoragem temporal tripla que o Observer adiciona em cada observação.
Compatibilidade com prompt caching. RAG não cacheia bem porque o prompt muda a cada turno. Contexto longo cacheia parcialmente. Memória Observacional cacheia muito bem porque o prefixo (camadas 1 e 2) é append-only e estável.
Custo por turno. RAG tem custo médio (embedding mais retrieval). Contexto longo tem custo alto (tokens vezes número de sessões). Memória Observacional tem custo baixo (compressão de 3-40x mais o desconto de caching de até 90%).
Infraestrutura necessária. RAG exige alta (vector store, pipeline de embedding, lógica de chunking). Contexto longo é mínimo. Memória Observacional também é mínima, precisa só de SQL, ou compatível.
Forgetting seletivo (esquecer o que não importa). RAG é ruim, depende do threshold arbitrário. Contexto longo é nulo (mantém tudo). Memória Observacional é bom, com prioridade explícita por emoji.
Knowledge updates (lidar com mudança de preferência). RAG é ruim, versões antigas persistem no índice. Contexto longo é bom. Memória Observacional é bom, o Reflector resolve conflitos com prioridade pra observação mais recente.
A leitura honesta da Atlan Research sobre isso:
"'RAG is dead' overstates the case; 'naive RAG is the wrong tool for agent memory' is accurate."
RAG continua útil pra busca em documentos, Q&A sobre base de conhecimento estático, recuperação de informação factual em corpus amplo. O problema é usar RAG ingênuo como sistema de memória conversacional pra agente. Pra esse caso de uso específico, OM ganha consistentemente, e o número 94,87% no LongMemEval é a evidência mais forte.
A inspiração biológica que não é só metáfora
O design Observer/Reflector tem raízes em pesquisa de memória humana, e isso não é casual. O paper "Position: Episodic Memory is the Missing Piece for Long-Term LLM Agents" argumenta que LLMs têm memória semântica adequada (fatos do treinamento) e memória procedural implícita (capacidades aprendidas), mas falta memória episódica, ou seja, a capacidade de lembrar experiências específicas com contexto temporal e causal.
A OM implementa exatamente isso. O Observer cria registros episódicos (eventos específicos com timestamp). O Reflector eventualmente consolida episódios repetidos em memória semântica (padrões sobre o usuário).
O mecanismo biológico análogo é fascinante. Durante o sono, o hipocampo humano "replaya" experiências do dia e as consolida no córtex como memória de longo prazo. Observer é equivalente ao encoding episódico no hipocampo. Reflector é equivalente à consolidação cortical noturna. É arquitetura cognitiva sendo transplantada pra software, com um nível de fidelidade que poucas abordagens conseguem.
Implementação prática
Pra quem quer experimentar, o setup mínimo no Mastra é uma linha:
import { Memory } from '@mastra/memory'
import { Agent } from '@mastra/core/agent'
const agent = new Agent({
name: 'my-agent',
instructions: '...',
model: 'openai/gpt-5-mini',
memory: new Memory({
options: {
observationalMemory: true,
},
}),
})
Configuração avançada permite controlar threshold, buffering, modelos por tier, escopo (thread isolado versus resource compartilhado entre threads), e modo de recuperação híbrido (OM mais RAG seletivo quando o agente decide que precisa de detalhe que a observação comprimiu).
Storage suportado: PostgreSQL (@mastra/pg), SQLite (@mastra/libsql), MongoDB (@mastra/mongodb). Nenhum vector store obrigatório, o que reduz drasticamente a barreira de adoção.
O que isso muda na prática do AI engineer
Eu venho usando memória observacional no dia a dia em chats internos, em conversas com nossos multi-agentes pra atendimento e respostas automatizadas. Três efeitos práticos que vale destacar.
Primeiro, o agente passa a "lembrar" de coisa que importa. Preferência declarada do usuário no turno 3 ainda está lá no turno 200, e o agente não precisa adivinhar. Isso muda a percepção do usuário sobre o produto. Ele começa a sentir que está falando com algo que aprende, não com algo que esquece a cada login.
Segundo, a conta de API estabiliza. Antes da OM, conversas longas tinham custo crescente exponencial. Com OM, o custo por turno é praticamente constante, porque o prefixo cacheado fica estável e só o final muda. Em projeto que tive em mãos, isso reduziu o custo mensal em ~7x.
Terceiro, o time de produto descobre coisas sobre os usuários que antes ficavam invisíveis. As reflexões consolidadas viram um log de comportamento explícito, auditável, sem PII solto. Esse log já me ajudou a identificar padrões de adoção que nenhum dashboard tinha capturado.
O contraponto honesto: o Observer e o Reflector são agentes LLM, então têm custo de execução. Em volume muito alto de conversas, é possível que o custo dos agentes em background suba acima do que se economiza no caching. A mitigação é a seleção por tier (ModelByInputTokens), usar modelo barato pra conversa curta, escalar pra modelo mais capaz só quando a conversa cresce. E se o Observer for fraco, a qualidade das observações degrada toda a cadeia. Garbage in, garbage out aplicado à memória.
A conexão com a série
Esse artigo fecha um ângulo importante da série que venho construindo nas últimas semanas. Falei sobre harness (o veículo em torno do modelo),