Em escala, agente em produção raramente cai por causa do LLM. Cai porque o contexto não foi desenhado pra escalar junto. O vector store envelhece em segundos, o banco transacional começa a apanhar com chamada de retrieval, a memória da sessão evapora, o cache semântico devolve resposta de outro caso. Tudo isso é arquitetura. Nenhum modelo melhor resolve.
Se você construiu um agente de suporte que responde rápido sobre a documentação, mas inventa quando o cliente pergunta "qual o status do meu pedido?", você já bateu no teto do RAG tradicional. O problema não são embeddings ruins. É que o snapshot que alimentou seu vector store ficou velho em segundos, e a arquitetura inteira foi montada assumindo que dado é estável.
A Redis acabou de lançar uma resposta a esse problema, e ela tem nome: Iris. É a primeira tentativa séria da indústria de cristalizar contexto de agente como categoria de infraestrutura, no mesmo nível que banco, fila e cache sempre foram pra aplicação web.
Eu venho escrevendo sobre as peças desse quebra-cabeça há meses. No artigo sobre por que seu RAG acerta 34% quando podia acertar 91%, o ponto era que pipeline mata o LLM antes do LLM ter chance. Na análise sobre convergência de agent harnesses, mostrei que os quatro principais (Pi, OpenClaw, Claude Code, Letta) convergem em quase tudo sobre gestão de contexto. Iris é a primeira tentativa séria de oferecer infraestrutura pronta pra esse problema, e a divisão de águas que ela cristaliza vale entender antes do próximo projeto.

A virada conceitual: build-time vs runtime
RAG tradicional, e até o que o mercado começou a chamar de "agentic RAG", faz um movimento essencialmente offline.
Fontes → scrape → chunk → embed → vector store (artefato pré-compilado)
Funciona bem com documentação estável. Quebra feio com dados operacionais voláteis: pedidos, tickets, billing, inventário, status de pipeline. O snapshot que alimentou o índice ficou velho na hora em que o agente foi consultar.
Iris inverte o sentido do fluxo:
Sistema de registro (Postgres/Oracle/Snowflake/Mongo) → CDC em tempo
quase real → cópia operacional viva em Redis → entidades navegáveis
via MCP → agente consulta o estado atual
Essa é a divisão que vai dominar 2026, e ela merece ficar clara na cabeça antes de qualquer decisão de stack.

No eixo build-time, o conhecimento entra offline, em lote. Pinecone Nexus é o representante recente: pega corpus enorme, indexa uma vez, serve por milhões de queries. Vence em documentação técnica, manuais, base de conhecimento estável. O custo dominante está no pré-processamento. O risco é staleness invisível.
No runtime, o conhecimento entra em tempo quase real via CDC. Redis Iris é o representante. Vence em customer support, e-commerce, billing, ticketing. O custo dominante é manter a réplica fresca. O risco é pressão no sistema transacional, mitigada justamente porque o agente lê da cópia, não da origem.
Não existe one-size-fits-all aqui. Stacks reais vão combinar as duas famílias. O que vai diferenciar é o engenheiro saber qual peça resolve qual fatia do problema.
Os quatro componentes do stack Iris
Iris não é um produto monolítico. É a junção orquestrada de quatro peças, cada uma com nome próprio e função distinta. Vale conhecer pelo nome porque a Redis está empurrando essa nomenclatura forte e a comunidade vai adotar.
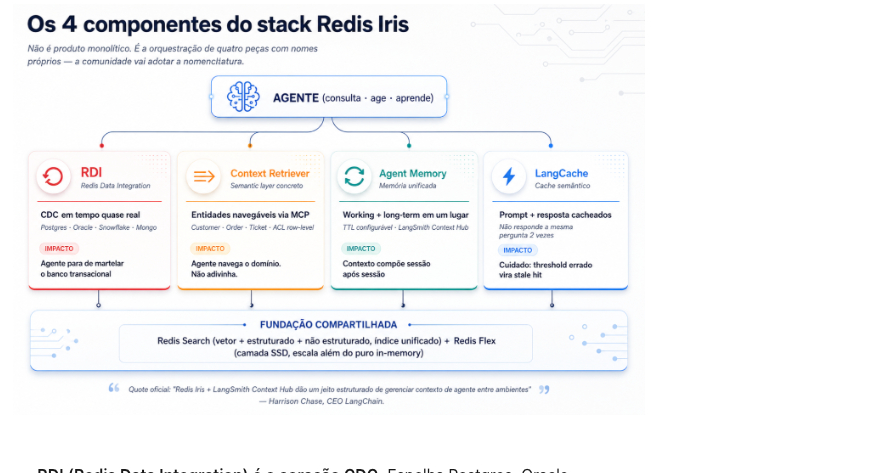
RDI (Redis Data Integration) é o coração CDC. Espelha Postgres, Oracle, Snowflake e MongoDB em Redis quase em tempo real. Por que importa: seus agentes deixam de martelar o banco transacional e passam a ler de uma cópia desenhada pra latência. Em produção, a diferença entre cravar a leitura no Postgres do ERP e ler de uma réplica Redis dedicada é a diferença entre o agente coexistir com o sistema crítico e o agente derrubar o sistema crítico.
Context Retriever é o semantic layer concreto. Você define entidades (Customer, Order, Ticket), campos, relacionamentos e ferramentas (find, get, search, filter) expostas via MCP ou CLI, com row-level access control. O agente navega o domínio, não adivinha. Isso é o que a Redis chama na página oficial de "navigable systems, not data silos": o diálogo direto com a query master sobre convergência de harnesses: quem oferece path explícito pro agente sempre vence quem força adivinhação por similaridade vetorial.
Agent Memory entrega memória curta e longa em um lugar só. Working memory pra contexto da sessão atual com TTL configurável. Long-term memory pra preferências do usuário, padrões aprendidos, dados promovidos entre sessões. A integração oficial com o LangSmith Context Hub, anunciada pela LangChain, dá versionamento de memória. Como o Harrison Chase (CEO da LangChain) escreveu, "Memory is core to how agents improve over time, and teams we work with are realizing they need scalable infrastructure behind it". Não é mais opcional pra agente de suporte de verdade.
LangCache é cache semântico de prompt e resposta. A mesma pergunta semanticamente não é respondida duas vezes pela LLM. Mas atenção: similarity threshold errado vira stale hit (resposta velha pra pergunta nova) ou out-of-context hit (resposta de outro caso entrando no lugar). Não é cache HTTP. Exige tuning de domínio antes de virar bala.
Embaixo de tudo: Redis Search como índice unificado (vetor + estruturado + não estruturado) e o novo Redis Flex, camada SSD que permite escalar além do puro in-memory com custo menor por GB armazenado. Flex é o detalhe que torna Iris adotável por empresas que ainda têm restrição de orçamento de RAM.
Os quatro requisitos pra retrieval agêntico em escala
Mesmo se você não for adotar Iris, a taxonomia que a Redis publicou na página de lançamento serve como checklist técnico pra qualquer arquitetura de agente em produção.

Navegabilidade. O agente precisa explorar entidades e relações, não só rodar top-k vetorial. Quem só oferece busca por similaridade está vendendo retrieval de 2023.
Velocidade. A Redis alega P95 menor que 250ms em produção. Vale exigir benchmark no seu workload antes de comprar a métrica, mas o ponto conceitual é correto: latência tem efeito bola de neve em loop multi-step. Quatro chamadas de 800ms numa cadeia agêntica já viraram 3,2 segundos por turno e o usuário desistiu.
Frescor. Dado operacional precisa refletir o sistema de registro em segundos, não em horas. Pra suporte, e-commerce, billing, isso é binário: ou tem, ou o agente alucina status.
Auto-melhoria. Contexto deve compor sessão após sessão. Sem long-term memory persistente, todo agente recomeça do zero cada conversa. É equivalente a contratar um suporte que esquece tudo a cada call. Ninguém aceita. Em agente, a maior parte do mercado ainda aceita.
Os asteriscos que ninguém imprime no slide
Toda solução nova chega com brilho de marketing. Vale tirar o brilho antes de decidir.
Iris não é plug-and-play. Você modela entidades, configura CDC, escreve as ferramentas que o agente vai usar. É infraestrutura, não SaaS chave-na-mão. Tempo de POC real, com integração no sistema de registro, dificilmente fica abaixo de duas a quatro semanas pra time pequeno.
Latência menor que 250ms é claim de vendor. Vale exigir benchmark no seu workload, principalmente se for usar Redis Flex (camada SSD). A diferença entre RAM e SSD de Redis aparece exatamente em workloads que estressam a cada P99.
LangCache exige cuidado em domínios onde a resposta certa há 30 segundos é a resposta errada agora. Billing dinâmico, inventário de varejo em pico de venda, status de pedido em entrega. Cache semântico nesses domínios precisa de TTL agressivo, e em casos extremos não deveria existir.
Row-level ACL em multi-tenant SaaS ainda é uma pergunta aberta na documentação pública. Vale POC antes de assumir que vai resolver isolamento de cliente por padrão.
E o ponto mais incômodo: toda essa stack pressupõe que você já tem sistema de registro confiável. Iris espelha o que o Postgres tem. Se o Postgres tem dado inconsistente, o Redis vai espelhar inconsistência mais rápido. A IA não conserta dado mal modelado a montante.
Por que isso importa pro próximo projeto que você vai aprovar
Se você está construindo um agente que precisa cruzar banco transacional, ticketing, shipping e documentos de política pra responder uma pergunta, e essa descrição cobre praticamente todo caso de customer support real, o stack vetorial-puro vai te decepcionar. Não porque a tecnologia é ruim, porque foi desenhada pra um problema diferente.
A pergunta que Iris obriga você a fazer não é "qual vector store devo escolher?". É:
Quanto do meu conhecimento muda por hora, e onde isso muda?
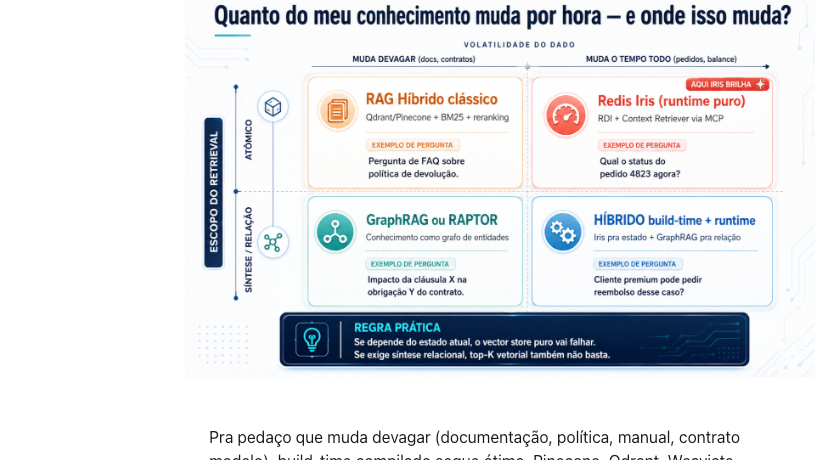
Pra pedaço que muda devagar (documentação, política, manual, contrato modelo), build-time compilado segue ótimo. Pinecone, Qdrant, Weaviate, pgvector. A escolha entre eles influencia 5 a 10% da qualidade final, como já escrevi antes. O que importa é chunking, busca híbrida, reranking e prompt.
Pra pedaço que muda a tempo todo (estado operacional, pedido, ticket, inventário, balance), runtime fresh-on-demand vira o caminho natural. E aqui Iris é a primeira aposta forte da indústria.
A maioria dos sistemas reais vai precisar das duas coisas. O agente de suporte que responde sobre política de devolução (build-time) e ao mesmo tempo sobre status do pedido específico do cliente (runtime). Quem entender essa divisão vai montar arquitetura híbrida com clareza. Quem não entender vai ficar tentando forçar uma família a fazer o trabalho da outra, e culpando "alucinação" quando o problema é arquitetura.
A pergunta que vale levar pra reunião amanhã
Três perguntas práticas pra líder técnico que tem agente em produção ou prestes a ir pra produção:
Primeira: qual percentual das perguntas que o seu agente recebe depende de dado operacional fresco (status, posição, balance, ticket aberto)? Se for acima de 30%, RAG puro vai falhar nesses 30%, e o cliente vai lembrar dos 30%, não dos 70% que acertou.
Segunda: como você descobre hoje que o snapshot do vector store está velho? Se a resposta envolve cliente reclamando, você não tem o sensor. Iris (ou qualquer arquitetura CDC equivalente) resolve por design.
Terceira: quanto custa pro seu negócio o agente responder "o pedido 4823 está em separação" quando o pedido já saiu pra entrega há duas horas? Se o número assusta, você não pode mais protelar a discussão sobre arquitetura de runtime context.
O futuro próximo do retrieval agêntico é híbrido por design. Build-time pro estável, runtime pro vivo. Iris não é a única resposta possível, mas é a primeira que cristaliza a categoria. Vale entender o mapa antes da próxima compra de infraestrutura.
Fontes: página oficial do Redis Iris (redis.io/iris), anúncio LangChain + Redis sobre Context Hub, documentação pública de RDI, Context Retriever, Agent Memory e LangCache. Para fundamentação técnica em RAG, ver arXiv 2506.00054 (RAG Architectures Survey 2026) e arXiv 2603.07379 (SoK Agentic RAG). Sobre convergência de design em agent harnesses, ver post original de Aparna Dhinakaran (Arize) comparando Pi, OpenClaw, Claude Code e Letta.