A discussão de adoção de IA pra desenvolvimento ainda gira muito em torno da pergunta errada. Líder da eng pergunta qual modelo usar. Time troca Sonnet por Opus, troca Opus por GPT-5, mede a diferença num prompt isolado, conclui que "agora vai". Em produção, não vai. A entrega segue inconsistente, os bugs voltam, o code review vira inspeção visual de PR de 800 linhas e o time não consegue explicar por que metade do código gerado nunca chega ao merge.
O gargalo não é qual modelo. É o processo entre modelos.
Rodei um experimento de ponta a ponta pra provar isso. Montei um harness com três níveis de agência, modelos (LLMs) de diferentes propósitos em cada papel (inclusive um revisor de outro fornecedor LLM), gates de evidência reais e um único ponto de aprovação humana no início e outro no fim. Larguei um lote de 23 tarefas planejadas e deixei rodar. O que aconteceu: 4h48m de máquina, 23 tarefas entregues, 600+ testes verdes, 8 rodadas de code review, 21 achados remediados, 1 Pull Request aberto e totalmente documentado. Zero intervenção humana no desenvolvimento. Só planejamento na entrada e merge na saída.
Este artigo é o passo a passo desse harness, os princípios que generalizam e o detalhe do experimento que mais me marcou: o review convergiu.

A tese: qualidade não vem de modelo melhor, vem de processo melhor entre modelos
Sebastian Raschka publicou recentemente uma destilação que cola com tudo que venho falando: a pergunta sobre "LLM que responde" de "coding agent que entrega" não é o modelo, é o harness. Aparna Dhinakaran, fundadora da Arize, comparou o código fonte de quatro harnesses populares e descobriu que eles convergem em quase tudo (capo de leitura de arquivo, compactação de sessão LLM-powered, isolamento de subagente, gate de tool result). Já cobri os dois ângulos na série, no artigo sobre componentes de coding agent e no comparativo dos quatro harnesses.
Faltava o passo prático: um harness real, com três modelos em papéis diferentes, rodando ponta a ponta, instrumentado com relógio. É o que vou descrever aqui.
A tese é simples. Um LLM puro é motor de texto. Não tem memória de longo prazo, não garante que rodou os testes, não sabe quando parar e não tem noção de "pronto pra produção". Pede pra ele implementar uma feature inteira numa única passada e ele tenta, falha nos detalhes, esquece um teste, inventa um caminho de arquivo, declara sucesso sem evidência. O harness é a moldura ao redor do modelo que resolve isso. Provê orquestração, isolamento, gates de verificação, loop de review, divergência e dois pontos de decisão humana bem escolhidos. O LLM é o músico. O harness é o "maestro", a partitura e as regras do palco. Música genial sem regência produz ruído num conjunto grande.
A consequência prática dessa tese, que ainda não está absorvida pela maioria dos times de eng, é a seguinte. Trocar Sonnet por Opus num prompt cru muda pouco. Trocar de modelo dentro de um harness bem desenhado muda muito, porque cada papel passa a usar o motor certo pro trabalho certo. Raciocínio e julgamento num modelo forte. Implementação em massa num modelo rápido. Revisão num modelo de outro fornecedor. É defense-in-depth, conceito antigo de segurança aplicado à IA.
A arquitetura: três níveis de agência, modelos diferentes em cada um
O harness tem três níveis, e o ponto central é que cada nível pode (e deve) rodar num modelo diferente.
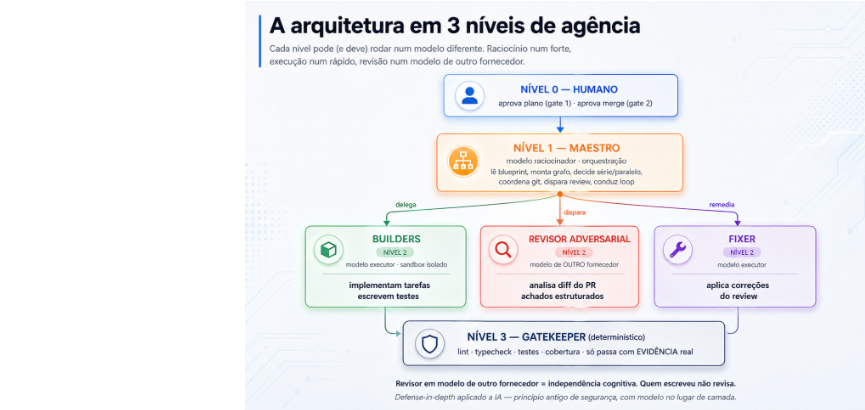
No nível 0 está o humano. Aprova o plano, aprova o merge, arbitra trade-offs ambíguos. Dois gates, não vinte.
No nível 1 está o orquestrador, modelo raciocinador, o que conduz o fluxo. Lê o blueprint do lote, monta o grafo de dependências, decide série versus paralelo, coordena git, dispara o review e conduz o loop de remediação. Não escreve código. Não revisa código. Coordena os componentes que fazem.
No nível 2 estão três tipos de subagentes em paralelo. Os Builders são modelos executores, rápidos e baratos, rodando em sandbox isolado, cada um implementando uma tarefa específica. O Revisor adversarial é um modelo de outro fornecedor, que recebe o diff do PR e emite uma saída estruturada de achados com severidade, tipo de risco e solução proposta. O Fixer, também executor, aplica as correções dos achados válidos e re-verifica.
No nível 3 estão os componentes determinísticos. O Gatekeeper roda lint, typecheck, testes, cobertura. Só deixa passar com evidência real. Sem ele, nada é "concluído".
A escolha de outro fornecedor pro Revisor é deliberada. Um modelo tende a aprovar padrões parecidos com os que ele mesmo gera. Trocar a família de modelo no papel de revisor e o orquestrador humano de pedir code review pra alguém que não participou da implementação. É como você pega viés sistêmico que o autor cego não enxerga. Anthropic descreveu o padrão geral como orchestrator-workers no Building effective agents, e o twist de usar fornecedor diferente no revisor é o que dá ao processo a independência cognitiva que falta quando todo papel roda no mesmo modelo.
As 7 fases do fluxo
O harness executa um lote inteiro numa única invocação. Sete fases, dois gates humanos, tudo no meio é autônomo.
Fase 1, preflight e plano. O orquestrador lê o blueprint do lote (tarefas, critérios de aceite, dependências), monta o grafo, valida ciclos, calcula a ordenação topológica em camadas e decide o paralelismo. Apresenta o plano ao humano e espera aprovação. Gate 1.
Fase 2, setup de versionamento. Cria uma única branch de integração, uma issue por tarefa com critérios virando checklist desmarcado, e registra o mapeamento tarefa-issue.
Fase 3, execução topológica. Para cada camada do grafo, o orquestrador delega tarefas elegíveis aos Builders em sandboxes isolados. Tarefas com footprint disjunto rodam em paralelo, as que compartilham arquivo rodam em série. O Builder implementa, escreve testes, chama o Gatekeeper. Integração serializada, um commit atômico por tarefa.
Fase 4, abertura do PR. Push da branch, um único PR contra a branch padrão, corpo consolidando o lote com closes #N de cada issue. Se tem CI, faz polling, corrige falha, repete.
Fase 5, code review automático. Revisor adversarial analisa o diff, emite achados estruturados (severidade, arquivo, linha, recomendação), cada achado vira comentário inline no PR. Um resumo no topo serve de índice.
Fase 6, loop de remediação. O coração do harness, descrito na seção seguinte.
Fase 7, relatório e gate humano final. O orquestrador entrega o relatório, o PR fica aberto pra revisão humana. Gate 2. Não faz merge automático.
Série é o padrão, paralelismo é exceção autorizada pelo grafo
A regra de ouro do harness é contra-intuitiva pra quem pensa em concorrência como ganho automático. Série é o default. Paralelismo é exceção.
Duas tarefas só rodam em paralelo se três condições baterem: não há dependência entre elas, os arquivos que elas tocam são disjuntos e nada no enunciado pede execução sequencial. Na dúvida, série. A maior fonte de bug em orquestração concorrente é dois agentes escrevendo no mesmo arquivo ao mesmo tempo. Sandbox isolado por Builder previne colisão antes que aconteça, mas a integração de volta na branch é sempre serializada, um commit atômico por tarefa.
Esse padrão de isolamento de subagente convergiu nos quatro harnesses que Dhinakaran comparou (Pi, OpenClaw, Claude Code, Letta). Todos rodam o filho com a task string e nada mais do histórico do pai. Não é coincidência. É a única arquitetura segura quando o trabalho é concorrente. Falei sobre essa convergência no artigo dos quatro harnesses, mesmas respostas.
O loop que termina
Esta é a parte que mais impressiona quem lê sobre o workflow. O loop de remediação roda assim: o Revisor encontra achados, o Fixer remedia os válidos, o Gatekeeper re-verifica, o Revisor re-analisa o novo diff. Repete até veredito limpo, ou até só restarem achados que precisam de decisão humana, ou até bater o teto de rounds.
O teto importa. Sem ele, dois modelos podem ficar "discutindo" pra sempre, um corrige, o outro acha algo novo, ad infinitum. O teto converte o loop em um processo que termina. Default 3 rounds. Autonomia sem terminação é uma conta de cartão de crédito sem limite.
Esse princípio vale pra todo loop em sistema autônomo de IA, incluindo o loop de retry de CI, o de tentativa de correção de typecheck, o de re-tentativa de chamada de tool. Sem teto explícito, autonomia vira despesa descontrolada e debug impossível.
O experimento: 4h48m, 23 tarefas, 8 rodadas, 1 PR
Tudo que escrevi até aqui poderia ser só diagrama bonito. Então rodei um produto real, ponta a ponta, numa única sessão, com cada etapa cronometrada. O contrato foi rígido: o humano fez só o trabalho de pensamento de alto nível (PRD, ADRs, especificação técnica), num modelo de Spec-Driven Development parecido com o que o GitHub Spec Kit propõe. A partir do "go", o desenvolvimento inteiro rodou sem intervenção humana. Implementação, testes, revisão, refatoração, bugfix, documentação. Nenhum prompt no meio do caminho. O humano só voltou no fim, pro merge.
Os números:
Tempo total de ciclo: 4h48m. Desenvolvimento (plano + execução + verificação + PR): 3h02m. Code review nas 8 rodadas: 1h12m. Remediação dos achados: 33min.
Tarefas entregues: 23 de 23. Camadas topológicas do grafo: 8. Commits atômicos: 45 (um por tarefa mais os fixes). Suíte de teste verde: 600+ testes em três níveis (unitário, integração, ponta a ponta). Achados do review remediados: 21 de 21, com correções-bônus de causa raiz que o Revisor sugeriu além do reportado.
O que isso significa na prática. 4 horas e meia de máquina entregaram o que normalmente seriam dias de trabalho de um time pequeno. A inteligência humana foi gasta onde rende mais, no planejamento (o quê e por quê), e o harness cuidou do como (a execução repetitiva, verificável e cansativa). O review não foi carimbo. Foi interrogatório que produziu trabalho rastreável.
O detalhe mais interessante: o review convergiu
As 8 rodadas não ficaram repetindo os mesmos problemas. Foram ficando mais fundas, sem reincidência.
Rodada 1 e 2 pegaram boot, build, contratos. O que impede de subir. Rodada 3 e 4 pegaram ciclo de vida e concorrência. O que quebra sob carga. Rodada 5 e 6 pegaram empacotamento e deploy. O que quebra fora da minha máquina. Rodada 7 e 8 pegaram checkout limpo e DX. O que quebra pro próximo dev. Aí veio o veredito limpo e o PR foi pro gate humano.
Esse é o sinal de que o loop funciona como processo, não como ruído. A cada rodada o Revisor adversarial encontrava uma classe de problema mais profunda, exatamente os bugs de integração e runtime que testes unitários não pegam (sem browser, sem múltiplos contêineres conversando), e o harness corrigia, re-verificava, até veredito limpo. Não houve loop infinito. Houve convergência.
O modelo que revisou não foi o que escreveu. Em 8 rodadas, ele saiu de "isso nem sobe" pra "isso quebra pro próximo dev" e parou quando estava limpo. Isso é processo, não chute. E é a melhor evidência prática que vi até hoje de que a tese de Raschka aguenta peso real.
A honestidade do experimento
Nem tudo virou mágica, e essa parte importa muito mais do que parece. As integrações que dependiam de credenciais externas reais ficaram em modo degradado, parametrizadas e documentadas. O harness não inventou chave nem fingiu que funcionava. Sinalizou o que dependia de humano e seguiu com o resto.
Autonomia honesta é saber onde parar. O agente que inventa o que não tem pra "completar a tarefa" é o agente que quebra confiança em produção. O que sinaliza limite e segue com o que dá pra fazer é o que escala.
Esse é o mesmo padrão de evaluator agentic que faz a diferença entre um agente de atendimento que cobra cliente errado e um que pede confirmação humana. E é o mesmo princípio que está por trás da arquitetura de memória observacional, onde o Observer e o Reflector têm escopos delimitados e nunca tentam responder pelo agente principal.
Os princípios que generalizam
Quatro coisas que tiro desse experimento e que valem pra qualquer harness, não só o que rodei:
Orquestrar, não reimplementar. O orquestrador não escreve código nem revisa. Coordena componentes especializados. Cada peça faz uma coisa bem. Tentar fazer um agente que "faz tudo" é o caminho mais rápido pro "não faz nada direito".
Modelos diferentes pra papéis diferentes. Raciocínio num modelo forte, implementação em massa num modelo rápido, review num modelo de outro fornecedor pra independência cognitiva. Defense-in-depth aplicado à IA. O custo total cai porque o trabalho pesado vai pro modelo barato e o trabalho fino vai pro modelo caro só onde precisa.